Verarbeitung großer Datenmengen im IoT-Bereich
hintergrund
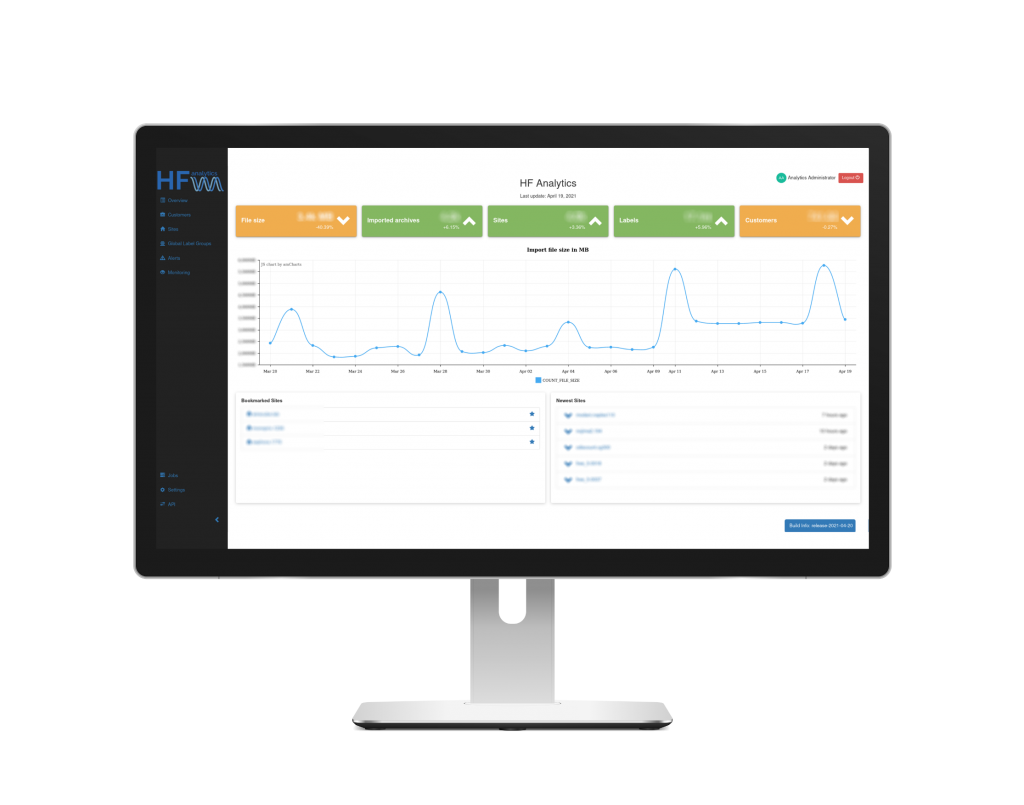
Ein Kunde mit Millionen von IoT Geräten bekommt täglich Log-Daten in großen Mengen. Mit diesen Daten sollen Erkenntnisse in verschiedenste Bereiche erarbeitet werden. Beispiele hierfür sind zum einen eine kompakte und intuitiv verständliche Übersicht über den Zustand der aktiven Geräte, sowie Prognosen über die weitere Benutzung und der vorraussichtlich verbleibenden Lebenszeit. Mit letzterem stark in Zusammenhang ist auch der Wunsch frühzeitig fehlerhafte bzw. auffällige Installationen zu detektieren.
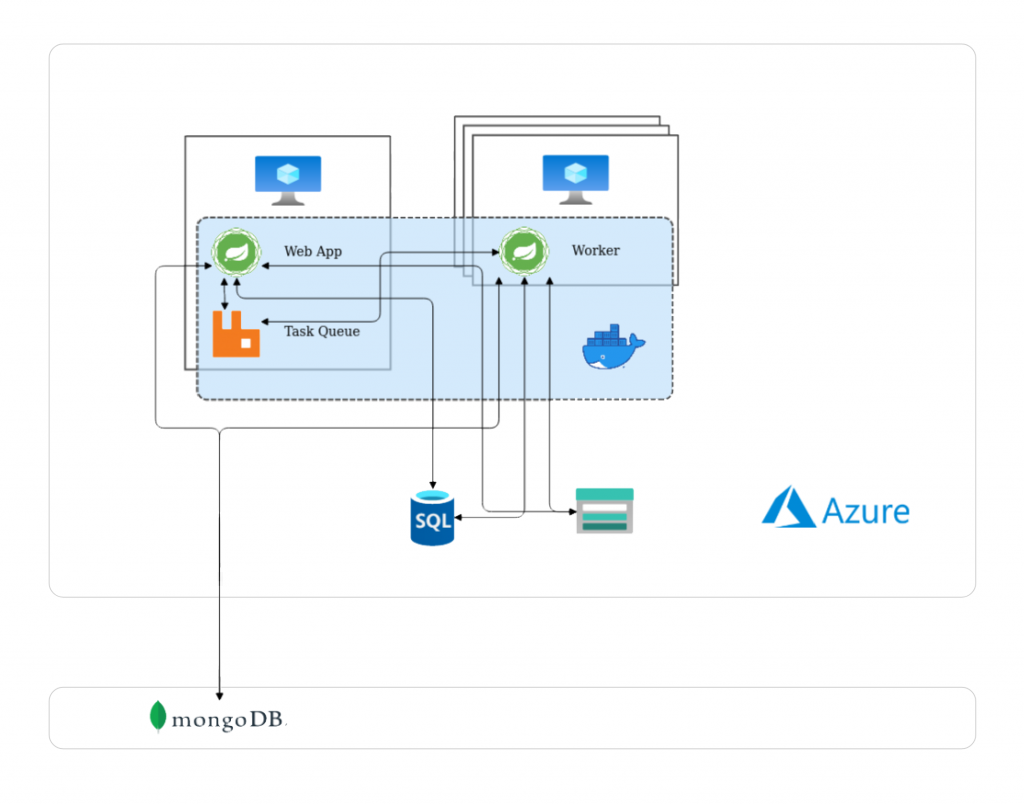
Die Ausgangslage war eine bereits zuvor existierende Spring Boot Applikation, die daraufhin stark erweitert und ausgebaut wurde. Die Vorteile verschiedener Datenbanktechnologien wurden ausgenutzt um zum einen die Präsentation und Verwaltung von hierarchischen Daten (MySQL) und zum anderen das effiziente Speichern und Rechnen mit großen Datenmengen (NoSQL – MongoDB) optimal zu gewährleisten. Die Applikation wurde aufgeteilt in einen Webapp-Teil, der die Präsentation von Daten und die Koordination von Aufgaben erledigt, und einen Worker-Teil, der die klassichen Extract-Transform-Load (ETL) Operationen übernimmt. Dies ermöglicht auch bessere Skalierung, da die Anzahl der laufenden Worker beliebig angepasst werden kann. Zur Koordination der Aufgaben kam weiters auch ein Message Broker (RabbitMQ) zum Einsatz. Mit dieser Architektur konnten hunderte GB an Daten stabil verarbeitet und aufbereitet werden.
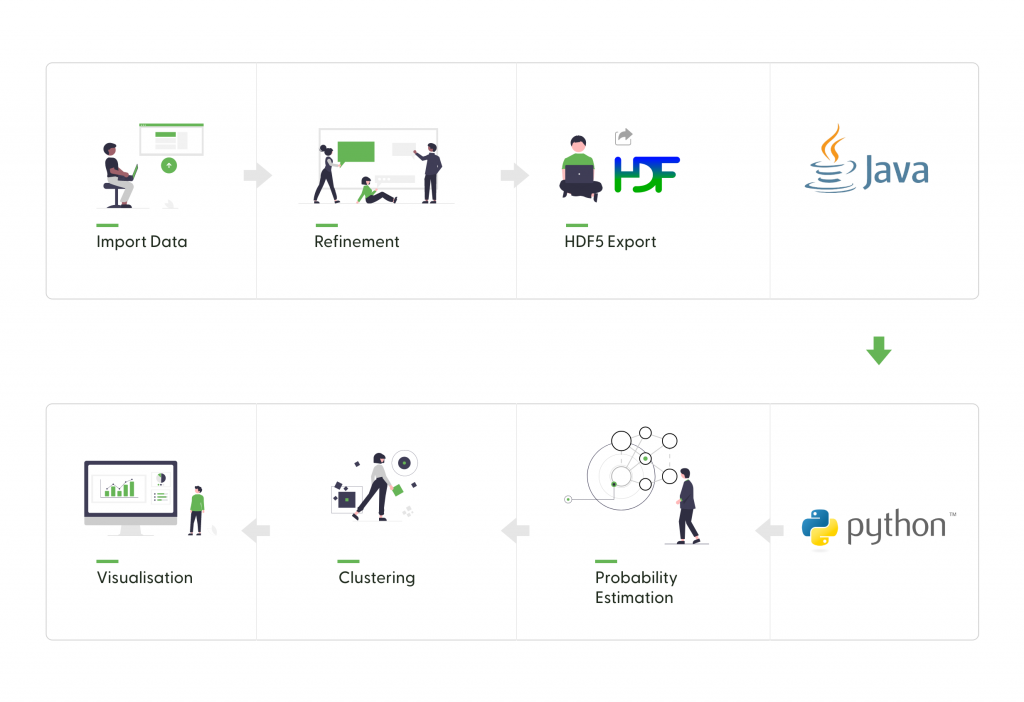
Um die Problemstellung der Festellung von aufälligen Installation zu lösen, griffen wir auf einen bereits zuvor implementierten Prototyp eines Anomaly Detection Frameworks zurück. Durch das Lernen von typischen Daten mittels eines Distribution-Estimators (NADE) können neu auftauchenden Datenpunkten Wahrscheinlichkeiten zugeschrieben werden. Um aus der resultierenden Datenmenge zusammenhängende Gruppen von möglichen Fehler zu finden, wurde ein Clustering Verfahren implementiert, welches auf die konkrete Problemstellung zugeschnitten war.