High-Volume IoT Data Processing
BACKGROUND
A customer with millions of IoT devices receives log data in large quantities every day. This data is to be used to gain insights into a wide range of areas. Examples of this are a compact and intuitively understandable overview of the status of the active devices, as well as forecasts about further use and the expected remaining lifetime. The latter is also strongly related to the wish to detect faulty or conspicuous installations at an early stage.
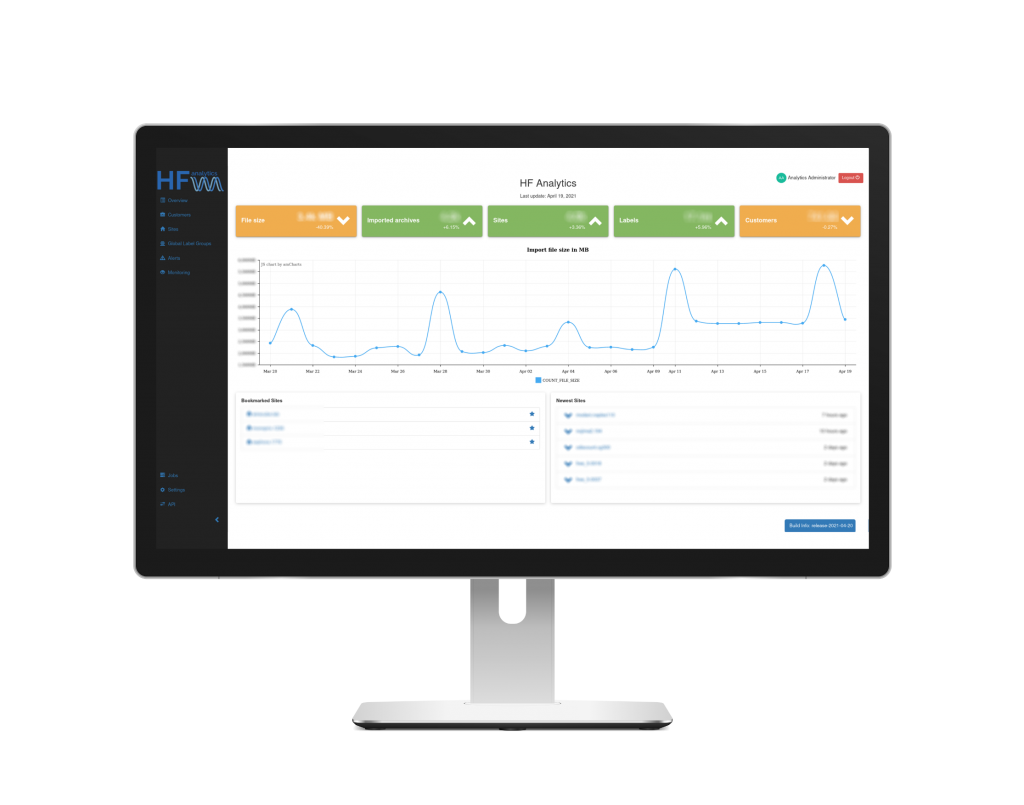
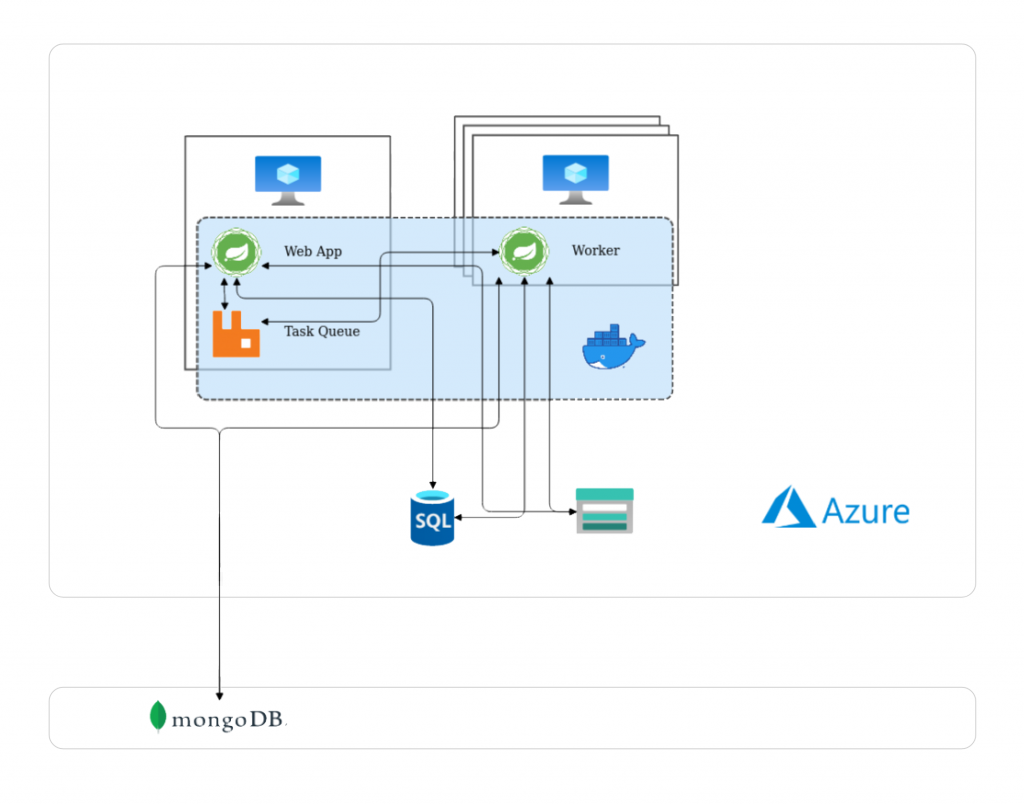
The starting point was a pre-existing Spring Boot application, which was then significantly extended and expanded. The advantages of different database technologies were exploited to optimally ensure the presentation and management of hierarchical data (MySQL) on the one hand and the efficient storage and calculation of large data volumes (NoSQL – MongoDB) on the other. The application was split into a webapp part, which handles the presentation of data and the coordination of tasks, and a worker part, which handles the classic Extract-Transform-Load (ETL) operations. This also allows for better scaling, as the number of running workers can be adjusted as needed. A message broker (RabbitMQ) was also used to coordinate the tasks. With this architecture, hundreds of GB of data could be stably processed and prepared.
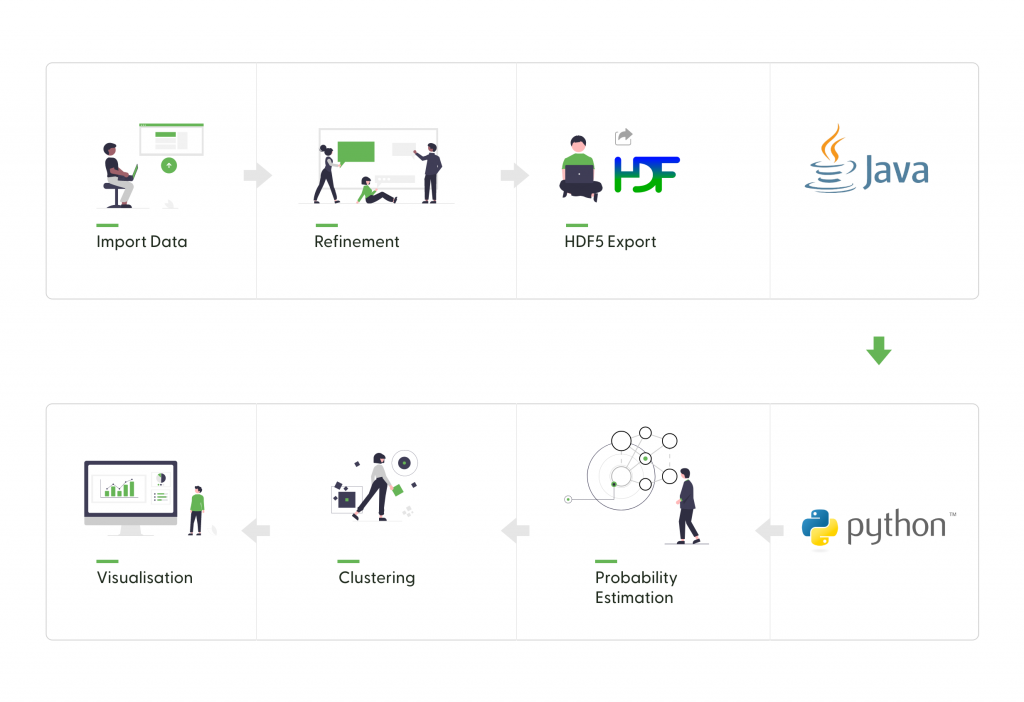
To solve the problem of detecting conspicuous installations, we relied on a previously implemented prototype anomaly detection framework. By learning from typical data using a distribution estimator (NADE), probabilities can be ascribed to newly emerging data points. In order to find coherent groups of possible errors from the resulting data set, a clustering procedure was implemented that was tailored to the specific problem.



Ready for Your
Success Story?
✓ free ✓ personal ✓ informal